
1. 인터넷 통신
클라이언트가 hello world를 보내면 서버에서는 ok 응답을 보내준다.

이 과정을 통해, 인터넷은 어떻게 통신을 할까?
서버가 하나만 있는 것도 아니고 많이 존재하는데 어떻게 찾아갈까?

2. IP(인터넷 프로토콜)
클라이언트에서 서버로 찾아가는 방법은 IP를 이용하는 것이다.
인터넷 프로토콜의 역할
- 인터넷 프로토콜은 지정한 IP 주소 (IP Adress)로 데이터를 전달한다.

IP로 서로 찾아간다.
- 패킷(Packet)이라는 통신 단위로 데이터를 전달한다.
- 출발 IP, 도착 IP, 전송 데이터로 구성된다.


IP 프로토콜의 한계
위의 그림을 보면 통신을 하는 과정에서 많은 노드를 거치게 되는데, 클라이언트와 서버가 서로 연결 안된걸 볼 수 있다.
이 과정에서 문제가 생기기도 한다.
비연결성
- 패킷을 받을 대상이 없거나 서비스 불능 대상이여도 패킷을 전송한다. (대상 서버가 패킷을 받을 수 있는지 알 수 없다)
비신뢰성
- 노드를 거치다가 해당 노드에 문제가 생겨서 중간에 패킷이 사라지면?
- 패킷이 순서대로 안오면? 패킷이 정해진 노드대로 오지않고 중간에 경로가 바뀔 수도 있다.
프로그램 구분
- 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 2개 이상이면?
3. TCP, UDP
이전에 언급된 IP 프로토콜의 한계를 해결해주는게 TCP와 UDP 이다.
먼저 IP 계층을 알아보자.

- 애플리케이션 계층 : HTTP, FTP
- 전송 계층 : TCP, UDP
- 인터넷 계층 : IP
- 네트워크 인터페이스 계층
프로토콜 계층
컴퓨터를 바라보면 간단하게 애플리케이션, 운영체제, 네트워크 관련된 구조로 3가지로 나눠진다.
여기서 채팅 프로그램을 통해 해외에 있는 친구에게 메시지를 보낸다면 다음과 같은 그림을 볼 수 있다.

순서대로 보면 HTTP -> TCP -> IP -> 이더넷프레임 차례대로 정보가 포함되어 서버로 전송이 된다.
IP 패킷 정보

IP 패킷 정보에는 출발지 IP, 목적지 IP 등를 포함한다.
* 패킷은 수하물을 뜻하는 패키지와 덩어리를 뜻하는 버킷의 합성어다.
TCP/IP 패킷 정보

TCP/IP 패킷은 IP 패킷 정보에 출발지 PORT, 목적지 PORT, 전송 제어, 순서, 검증 정보 등이 담긴다.
TCP는 전송 제어 프로토콜(Transmission Control Protocol)로 다음과 같은 특징을 가진다.
- 연결지향 - TCP 3 way handshake (가상 연결)

1. 클라이언트에서 서버로 SYN(접속 요청) 메시지를 보낸다.
2. 서버에서 클라이언트로 SYN+ACK 메시지를 보낸다.
3. 클라이언트에서 서버로 ACK 메시지와 데이터를 보낸다.
1,2 과정을 통해 서로 응답을 확인하고 나서 3번 과정을 통해 데이터를 보낸다.
* 실제로 물리적으로 연결된 게 아니라 개념적으로 연결이 된거다.
- 데이터 전달 보증

- 순서 보증

- 신뢰할 수 있는 프로토콜
- 현재 대부분 TCP 사용
UDP (User Datagram Protocol)
사용자 데이터그램 프로토콜로 다음과 같은 특징을 가진다.
- 하얀 도화지에 비유 (기능이 없다고 보면됨)
- 연결지향 - TCP 3 way handshake 없음
- 데이터 전달 보증도 하지 않음
- 순서 보장도 없음
- 그냥 단순하고 빠르다.
IP와 비교하자면
- PORT, 체크섬 정도만 추가된다.
- 애플리케이션에서 추가 작업이 필요하다.
4. PORT
지금까지 클라이언트와 서버로 1:1 통신을 기준으로 알아봤다.
그런데 보통 게임에서 팀으로 진행하면 게임 서버, 팀과 화상통화, 웹 브라우저로 게임 정보 검색 등 1:n 으로 통신하면 어떻게 해야할까?

동시에 여러 서버로 통신하면 어떻게 구분할까?
TCP/IP 정보를 다시 확인해보자.

IP만으로 구분하기 힘들기 때문에 출발지 PORT, 목적지 PORT가 존재한다.
정리하면 IP와 PORT 2가지로 구분하게 된다.
- 출발지 IP, PORT
- 목적지 IP, PORT
PORT란?
같은 IP 내에서 프로세스를 구분하는 걸 PORT라고 한다.

IP, PORT로 구분
PORT의 범위
0 ~ 65535 까지 할당이 가능하다.
0 ~ 1023는 기본적으로 사용하고 있기 때문에, 건들지 않는 것이 좋다. 다음은 대표적으로 사용 중인 PORT 번호다
- FTP - 20, 21
- TELNET - 23
- HTTP - 80
- HTTPS - 443
5. DNS (Domain Name System)
지금까지 IP로 클라이언트와 서버가 서로 통신하는 걸 알 수 있었다.
하지만 일반적인 사용자의 입장에서 인터넷을 사용할 때 생각해보면 IP 100.100.100.1 같은 주소를 외우긴 힘들다.
https://www.naver.com 같이 도메인 주소를 입력해서 인터넷을 사용하는 게 대부분이다.
또한 IP 주소는 변경이 될 수 있다.

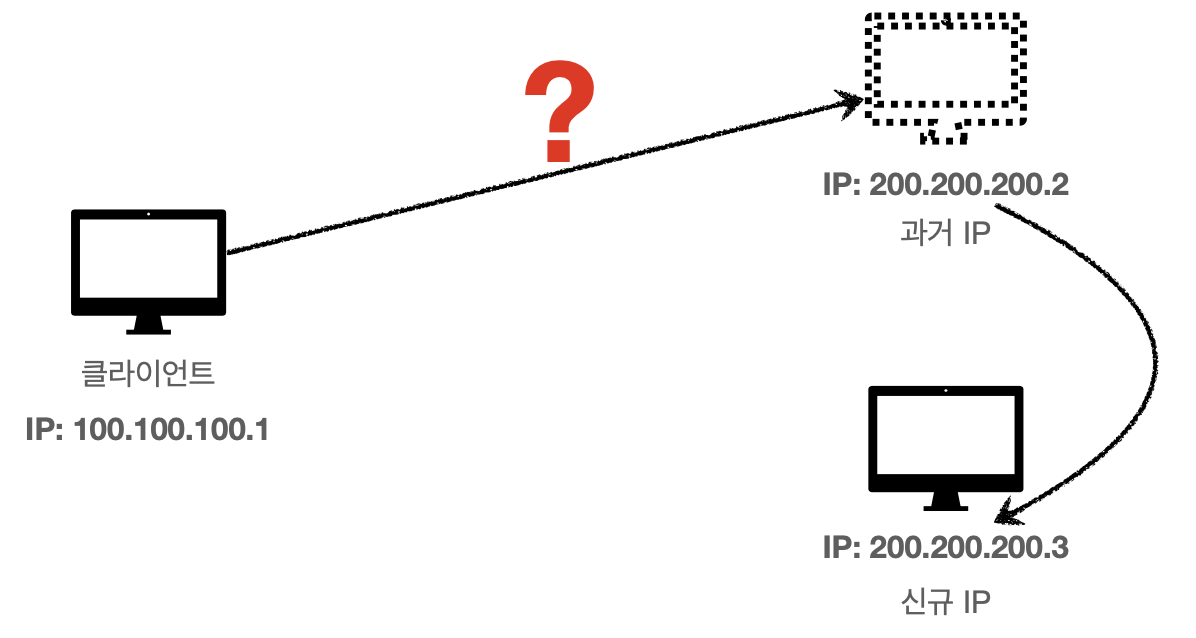
IP를 외워서 사용하기엔 많은 불편함이 있다.
이런 문제를 쉽게 해결해주는 것이 도메인 네임 시스템이다.
DNS이란?
IP 계의 전화번호부 역할을 한다.
도메인 명을 IP 주소로 변환시켜준다.

도메인 -> IP로 변환
6. URI(Uniform Resource Identifier)
리소스를 식별하는 통합된 방법이다.
URI? URL? URN?
비슷한 용어가 존재한다. 어떻게 구분할까?
URI는 로케이터(Locator), 이름(Name) 또는 둘 다 추가로 분류될 수 있다.
[https://www.ietf.org/rfc/rfc3986.txt]

URI 내부에 URL, URN 포함된다.
간단히 정리하면 다음과 같다.
URL - 리소스의 위치
URN - 리소스의 이름

URI 단어 뜻
- Uniform : 리소스 식별하는 통일된 방식
- Resource : 자원, URI로 식별할 수 있는 모든 것 (제한 없음)
- Identifier : 다른 항목과 구분하는데 필요한 정보 (주민번호 같은 것)
URL, URN 단어 뜻
- URL (Uniform Resource Locator) - 리소스가 있는 위치를 지정
- URN (Uniform Resource Name) - 리소스에 이름을 부여
- 위치는 변할 수 있지만, 이름은 변하지 않는다.
- URN 이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화되지 않음.
간단히 URI와 URL를 같은 의미로 이야기됨.
URL 분석해보자.
https://www.google.com/search?q=hello&hl=ko
hello - Google 검색
HELLO! brings you the latest celebrity & royal news from the UK & around the world, magazine exclusives, fashion, beauty, lifestyle news, celeb babies, ...
www.google.com

결과가 나온다.
URL 전체 문법
URL를 분석해보면 다음과 같은 구조가 나온다.
- scheme://[userinfo@]host[:port][/path][?qurey][#fragment]
- https://www.google.com:443/search?q=hello&hl=ko
scheme
- 주로 프로토콜에 사용
- 프로토콜 : 어떤 방식으로 자원에 접근할 것인지 약속 규칙
ex) http, https, ftp 등등
- http는 80 포트, https는 443 포트를 주로 사용, 포트는 생략이 가능하다
* https는 http에 보안이 추가된다. (HTTP Secure)
userinfo
- URL에 사용자 정보를 포함해서 인증
* 거의 사용하지 않음
PORT
- 접속포트
* 일반적으로 생략가능, 생략 시 http는 80, https는 443 이 붙음
path
- 리소스 경로(path), 계층적 구조를 갖는다. ex) /home/file1.jpg, /members, /members/100
qurey
- key=value 형태
- ?로 시작, &로 추가 가능하다 ex) ?keyA=valueA&keyB=valueB
- qurey parameter 혹은 query string 등으로 불림. 웹 서버에 제공하는 파라미터로 문자 형태
fragment
- html 내부 북마크로 사용됨
* 서버로 전송되는 정보는 아님
7. 웹 브라우저 요청 흐름
https://www.google.com/search?q=hello&hl=ko 요청하면 웹 브라우저는 어떻게 반응하게 될까?

1) URI를 입력한다.
2) DNS 서버로 IP를 알아온다. 생략된 PORT는 scheme로 찾아낸다.
3) HTTP 요청 메시지를 생성한다.

4) 클라이언트가 서버로 HTTP 메시지를 전송한다.
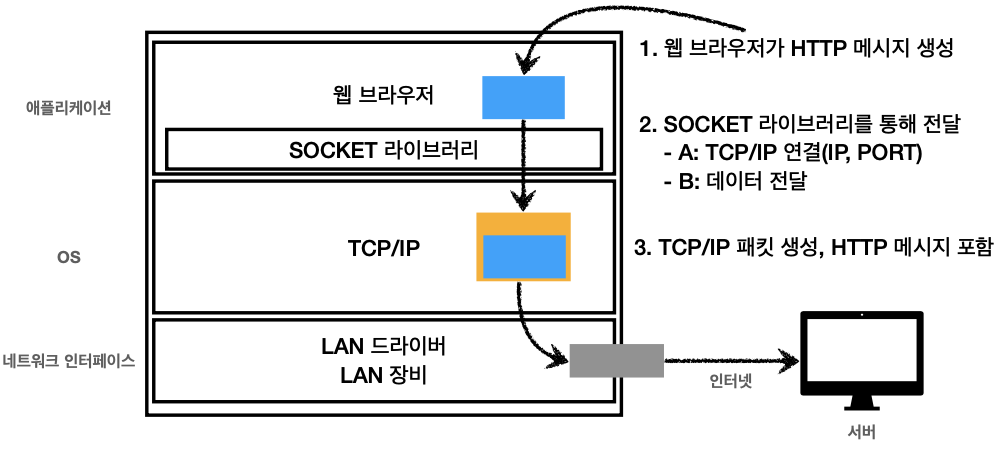

전달된 패킷은 서버에 도착되면 서버가 패킷 정보를 까서 HTTP 메시지를 확인한다.
5) 서버에서 클라이언트로 HTTP 응답 메시지를 전송한다. (응답 메시지는 자세한 사항은 다음 수업에)


서버에서 클라이언트로 HTTP 응답 메시지를 보낸다.
6) 클라이언트는 HTTP 응답을 받아서 웹 브라우저가 HTML 렌더링해서 보여준다.

'👩🏫 Study > 스프링부트 강의' 카테고리의 다른 글
| [3. HTTP 웹 기본 지식] HTTP 상태코드와 헤더 (0) | 2023.10.06 |
|---|---|
| [3. HTTP 웹 기본 지식] HTTP 기본과 메서드 (0) | 2023.10.06 |
| [2. 스프링 핵심 원리] 컴포넌트 스캔 (0) | 2023.10.05 |
| [2. 스프링 핵심 원리] 싱글톤 컨테이너 (0) | 2023.10.05 |
| [2. 스프링 핵심 원리] 스프링 컨테이너와 스프링 빈 (0) | 2023.10.04 |