
1. HTTP 상태코드
클라이언트가 서버로 보낸 요청의 처리 상태를 알려주는 기능
- 1xx (Informational) : 요청이 처리되어 수신 중 (거의 사용안함)
- 2xx (Successful) : 요청 정상 처리
- 3xx (Redirection) : 요청을 완료하려면 추가 행동이 필요
- 4xx (Client Error) : 클라이언트 오류, 잘못된 문법등으로 서버가 요청 수행을 못함
- 5xx (Server Error) : 서버 오류, 서버가 정상 요청을 처리 못함
만약에 모르는 상태 코드가 나타나면? 몇번대 상태코드인지만 보고 파악하자.
1xx 처리중이구나
2xx 성공했구나
4xx 클라이언트 오류구나
5xx 서버 오류구나
1) 2xx (Successful)
클라이언트 요청을 성공적으로 처리
200 ok : 요청을 성공했다는 뜻, 단순 조회 요청에 자주 접함

201 Created : 리소스 등록 요청에 성공

202 Accepted : 요청이 접수되었지만 처리가 안된 상태 (잘 사용안함)
ex) 배치 요청
204 No Context : 서버가 요청을 수행했지만, 응답으로 보낼 데이터가 없음.
ex) 문서 작업 중 save 눌러도 아무 변화없음, 결과 내용이 없어도 204 응답 메시지로 성공 인식 가능
* 200만 사용하는 회사도 있고 200,201을 같이 사용하는 회사도 있음. 회사마다 정하는 규칙에 따라 다름.
2) 3xx (Redirection)
요청을 완료하기 위해 유저 에이전트(웹 브라우저를 뜻함)의 추가 조치 필요
- 300 Multiple Choices
- 301 Moved Permanently
- 302 Found
- 303 See Other
- 304 Not Modified
- 307 Temporary Redirect
- 308 Permanent Redirect
리다이렉션의 이해
웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, 해당 Location로 이동한다.
리다이렉트라고 말하기도 함

1. 클라이언트가 요청을 보낸다.
2. 서버가 요청을 처리하고 3xx 상태코드와 Location 경로를 보내준다.
3. 웹 브라우저가 상태코드와 Location을 보고 해당 경로로 자동으로 요청을 보내고 응답을 받는다.
4. 너무 빨라서 사용자의 입장에서는 인식을 하기 힘들다.
리다이렉션의 종류
- 영구 리다이렉션 - 특정 리소스의 URI가 영구적으로 이동 ex) /members -> /users, /event -> /new-event
- 일시 리다이렉션 - 일시적인 변경 (PRG: Post/Redirect/Get) ex) 주문 완료 후 주문 내역 화면으로 이동
- 특수 리다이렉션 : 결과 대신 캐시를 이용
영구 리다이렉션
301, 308 상태코드를 가짐
리소스의 URI가 영구적으로 이동
원래의 URL를 사용안함, 검색 엔진 등에서도 변경 인지함.
301 Moved Permanently
리다이렉트시 요청 메서드가 GET으로 변하고, 본문이 제거될 수 있음(MAY)

308 Permanent Redirect
301과 기능은 같지만 요청 메서드와 본문 유지 (처음 POST로 보내면 리다이렉트도 POST도 유지)
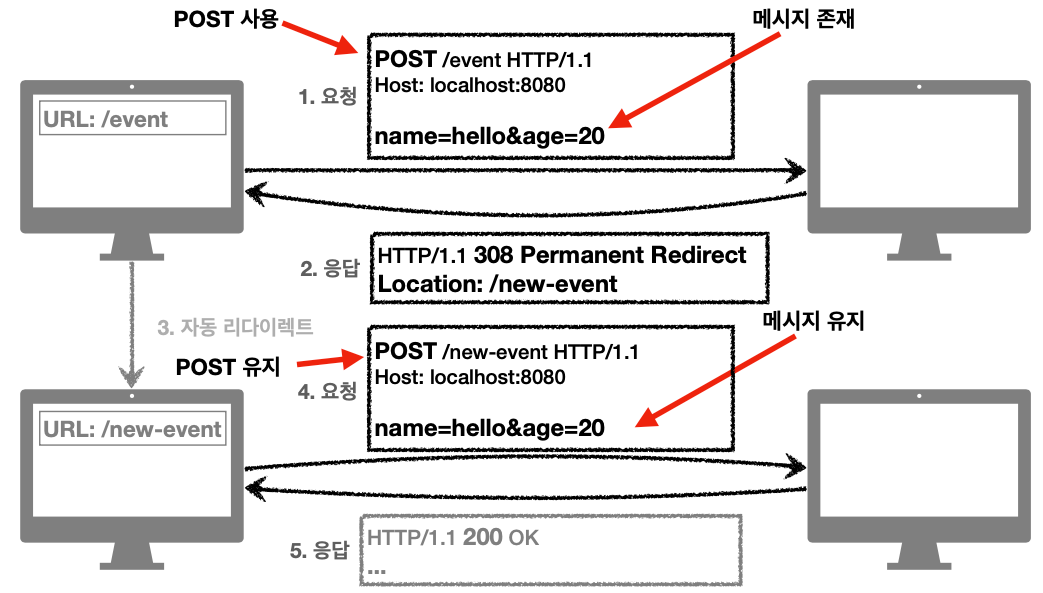
* 301 위주로 사용함, 요청 데이터까지 유지해야 할 이유가 별로 없기 때문
일시적인 리다이렉션
302, 307, 303 상태코드를 가짐
리소스의 URI가 일시적으로 변경, 영구적인 리다이렉션과 다르게 검색엔진 등에서 URL 변경하면 안됨
- 302 Found : 리다이렉트시 요청 메시지가 GET으로 변하고, 본문이 제거될 수 있음(MAY)
- 307 Temporary Redirect : 302와 기능은 같음, 리다이렉트시 요청 메서드와 본문 유지 (요청 메서드 변경하면 안됨)
- 303 See Other : 302와 기능은 같음, 리다이렉트시 요청 메서드가 GET으로 변경
일시적인 리다이렉션 - 예시
- POST로 주문 후에 웹 브라우저를 새로고침하면?
- 새로고침은 다시 등록 요청을 하게 됨 -> 중복 주문이 될 수 있다.
* 게시글이나 댓글을 등록할 때, 새로고침하면 중복으로 등록되는 경험을 겪어볼 수도 있다.

중복을 막는 PRG: POST/Redirect/Get
- POST로 주문후에 새로고침으로 인한 중복 주문 등록 방지
- POST로 등록 요청 후에 결과화면을 GET 메서드로 리다이렉트 (Post/Redirct/Get)
- 새로고침해도 등록 요청이 아닌 결과화면만 GET 조회하게 됨

302, 307, 303 뭘 써야 할까요?
처음의 302 스펙의 의도는 HTTP 메서드를 유지하는 것, 하지만 웹 브라우저들이 대부분 GET으로 바꿔버렸다 (일부는 다르게 동작) 그래서 302 대신 307, 303이 등장하게 됐다.
307, 303을 권장해도 많은 애플리케이션 라이브러리들이 302를 기본값으로 사용한다. 자동 리다이렉션시에 GET으로 변해도되면 그냥 302 사용해도 무방할 정도이다.
기타 리다이렉션
- 300 Multiple Choices: 안씀
- 304 Not Modified
- 캐시 목적으로 사용, 서버는 클라이언트에게 수정되지 않음을 알려줌
- 로컬 PC에 저장된 캐시로 리다이렉트해서 재사용함.
- 로컬 캐시를 사용해야 하니 응답에 메시지 바디를 포함안함.
- 조건부 GET, HEAD 요청시에 사용함
3) 4xx (Client Error)
클라이언트의 오류일 경우 사용한다.
클라이언트가 잘못된 요청으로 서버가 요청을 수행할 수 없을 경우 (오류의 원인이 클라이언트)와 같은 요청을 보내도 계속 실패하는 경우이다.
* 서버에서 유효성 검사로 철저하게 쳐냄
400 Bad Request : 요청 구문, 메시지 등등 오류, 클라이언트는 요청을 재검토해서 보내야함.
401 Unauthorized
- 클라이언트가 해당 리소스에 대한 인증이 필요함
- 인증되지 않음
- 401 오류 발생 시 응답에 WWW-Authenticate 헤더와 함께 인증 방법을 설명
403 Forbidden
- 서버가 요청을 이해했지만 승인을 거부함
- 인증은 되지만, 접근 권한이 안 되는 경우 ex) 일반 관리자가 최고 등급 관리자 리소스에 접근할 경우
404 Not Found
- 요청 리소스를 찾을 수 없음
- 요청 리소스가 서버에 없음
- 또는 해당 리소스를 숨기고 싶을 때
4) 5xx (Server Error)
- 서버 오류
- 서버 문제로 오류가 발생
- 4xx와 다르게 재시도하면 성공할 수도 있음 (서버가 복구되면)
* 참고 : 결제 요청 시 고객의 잔액이 부족하면 5xx 에러를 내면 안 된다.
500 Internal Server Error : 서버 문제로 오류 발생, 애매하면 모두 500 에러
503 Service Unavailable : 서비스 이용 불가
- 서버가 과부하 되었거나, 배포 작업 등으로 이용 못할 경우 사용
- Retry-After 헤더 필드로 언제 복구되는지 보낼 수도 있음.
2. HTTP 헤더 - 일반헤더

용도
HTTP 전송에 필요한 모든 부가정보가 헤더에 포함된다 ex) 메시지 바디의 내용, 크기, 압축, 인증 등등...
표준 헤더가 너무 많다.
분류 헤더는 다음과 같이 구분된다
- General 헤더 : 메시지 전체에 적용되는 정보, 예) Connection: close
- Request 헤더 : 요청 정보, 예) User-Agent: Mozilla/5.0 (Macintosho; ..)
- Response 헤더 : 응답 정보, 예) Server: Apache
- Entity 헤더 : 엔티티 바디 정보, 예) Content-Type: text/html, Content-Length: 3423

메시지 본문 - RFC2616(과거)
- 메시지 본문(message body)은 엔티티 본문(entity body)을 전달하는 데 사용함.
- 엔티티 본문은 요청이나 응답에 전달할 실제 데이터 ex) html, json
- 엔티티 헤더는 엔티티 본문의 데이터를 해석할 수 있는 정보 제공 (데이터 유형, 데이터 길이, 압축 정보 등)

1999년 RFC2616 표준은 현재 폐기되고, 2014년 RFC7230~7235 등장했다
HTTP BODY - REF7230(최신)
메시지 본문을 통해 표현 데이터 전달
메시지 본문 = 페이로드(payload) - 표현은 요청이나 응답에서 전달할 실제 데이터
표현 헤더는 표현 데이터를 해석할 수 있는 정보 제공 (데이터 유형, 데이터 길이, 압축 정보 등)
*참고사항 : 표현 헤더는 표현 메타데이터와, 페이로드 메시지를 구분해야 하지만 여기선 생략됨

1) 표현
Content-Type : 표현 데이터의 형식
Content-Encoding : 표현 데이터의 압축 방식
Content-Language : 표현 데이터의 자연 언어
Content-Length : 표현 데이터의 길이 - 표현 헤더는 전송, 응답 둘 다 사용

Content-type
표현 데이터의 형식을 설명함.
- text/html; charset=utf-8
- apllicationjson
- image/png

Content-Encoding
- 표현 데이터의 인코딩
- 표현 데이터를 압축하기 위해 사용
- 데이터를 전달하는 곳에서 압축 후 인코딩 헤더 추가
- 데이터를 받는 곳에서 인코딩 헤더의 정보로 압축을 해제 ex) gzip, deflate, identity

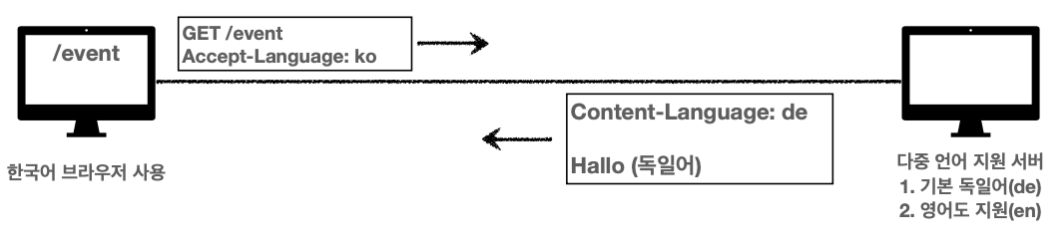
Content-Language
표현 데이터의 자연 언어를 표현
ko, en, en-US ex) 다국적 사이트에서 국가별 언어 선택

Content-Length
- 표현 데이터의 길이를 바이트 단위로 나타냄
- Transfer-Encoding(전송 코딩)을 사용하면 Content-Length를 사용하면 안됨. (전송 코딩안에 정보가 포함되어 있다 함)
2) 콘텐츠 협상
클라이언트가 선호하는 표현 요청
- Accept : 클라이언트가 선호하는 미디어 타입 전달
- Accept-Charset : 클라이언트가 선호하는 문자 인코딩
- Accept-Encoding : 클라이언트가 선호하는 압축 인코딩
- Accept-Language : 클라이언트가 선호하는 자연 언어
- 협상 헤더는 요청 시에만 사용함



만약에 원하는 언어가 없다면?
한국어로 요청했는데 한국어가 없다면 어떻게 해야 할까?
협상과 우선순위 1
- Quality Values(q) 값을 사용한다.
- 범위 0~1 를 가지며, 클수록 높은 우선순위다. (생략하면 default 1)
- Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
- 1) ko-KR;q=1 (q 생략되어 1)
- 2) ko;q=0.9
- 3) en-US;q=0.8
- 4) en;q=0.7

협상과 우선순위 2
- 우선순위는 Accept에도 가능하다.
- 구체적이면 우선순위가 높다
- Accept: text/*, text/plain, text/plain;format=flowed, */*
- 1) text/plain;format=flowed
- 2) text/plain
- 3) text/*
- 4) */*
협상과 우선순위 3
- 구체적인 것을 기준으로 미디어 타입을 맞춘다. (잘 사용 안 한다)
- Accept: text/*;q=0.3, text/html;q=0.7, text/html;level=1,text/html;level=2;q=0.4, */*;q=0.5
| Media Type | Quality |
| text/html;level=1 | 1 |
| text/html | 0.7 |
| text/plain | 0.3 |
| image/jpeg | 0.5 |
| text/html;level=2 | 0.4 |
| text/html;level=3 | 0.7 |
* 서버에서 제공하는 우선순위를 알고 있어야 한다.
3) 전송 방식
전송은 크게 4가지로 나눠진다.
- 단순 전송
- 압축 전송
- 분할 전송
- 범위 전송
단순 전송 : Content-Length를 알 수 있을 때 사용한다.

분할 전송 : Transfer-Encoding, 서버가 분할해서 응답을 보낸다. (용량이 클 때 사용)
* 분할해서 보내기 때문에 길이를 알 수 없어서 Content-Length는 사용할 수 없다.

범위 전송 : Range, Content-Range 범위를 지정해서 요청한다.

4) 일반 정보
From , 유저 에이전트의 이메일 정보
일반적으로 잘 사용되지 않음.
검색 엔진 같은 곳에서 주로 사용 (누군가 크롤링하면 연락할 방법을 찾기 위해서)
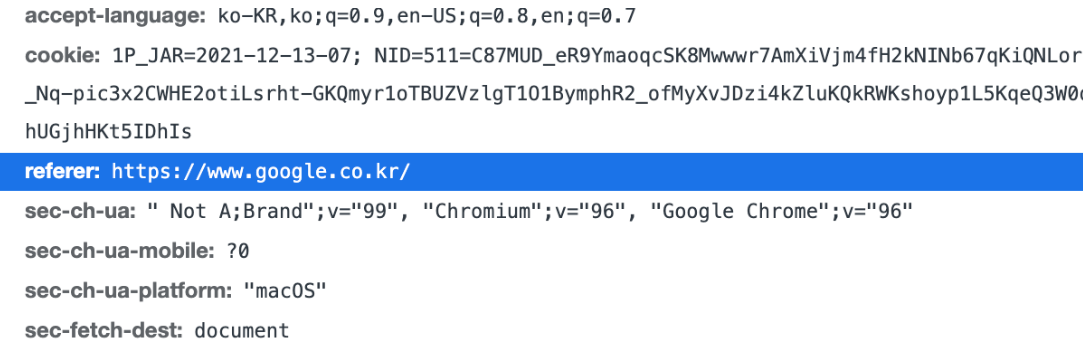
Referer , 이전 웹 페이지 주소
현재 요청된 페이지의 이전 웹 페이지 주소
A -> B로 이동하는 경우 B를 요청할 때 Referer: A를 포함해서 요청
Referer를 사용해서 유입 경로 분석 가능 (데이터 분석에 사용) - 요청에서 사용함
* 참고 : referer은 referrer의 오타
User-Agent , 유저 에이전트 애플리케이션 정보
- 클라이언트 애플리케이션 정보(웹 브라우저 정보, 등등)를 뜻함.
- 버그가 발생하면 어떤 종류의 브라우저에서 발생하는지 파악 가능
- 사용자의 브라우저 통계 분석 가능.
- 요청에서 사용

Server, 요청을 처리하는 ORIGIN 서버의 소프트웨어 정보
- Server: Apache/2.2.22 (Debian)
- 응답에서 사용

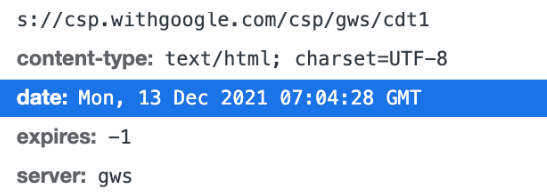
Date, 메시지가 발생한 날짜와 시간
응답에서만 사용
5) 특별한 정보
Host, 요청한 호스트 정보(도메인)
- 요청에서 사용, 필수값
- 하나의 서버가 여러 도메인을 처리해야 할 때 ex) 하나의 IP에 여러 도메인이 있을 때

Location, 페이지 리다이렉션
웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, Location 위치로 자동 이동 (리다이렉트)
201 (Created) : Location 값은 요청에 의해 생성된 리소스 URI
3xx (Redirection) : Location 값은 요청을 자동으로 리디렉션하기 위한 대상 리소스를 가리킴 * 자세한 내용은 이전을 참고
Allow, 허용 가능한 HTTP 메서드
405 (Method Not Allowed)에서 응답에 포함해야 함
Allow : GET, HEAD, PUT * 많이 구현된 서버가 없다.
Retry-After, 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
503 (Service Unavailable) : 서비스가 언제까지 불능인지 알려줄 수 있음
날짜 표기 Retry-After: Fri, 31 Dec 1999 23:59:59 GMT
초단위 표기 Retry-After: 120
6) 쿠키
Set-Cooike : 서버에서 클라이언트로 쿠키 전달(응답)
Cookie : 클라이언트가 서버에서 받은 쿠키를 저장하고, HTTP 요청시 서버로 전달
쿠키를 사용 안 하면


원인은 HTTP 무상태 프로토콜이기 때문! 상태 유지를 위한 대안 필요하다.
대안1. 모든 요청에 사용자 정보 포함

요청에 사용자 정보 포함하는 문제점 - 모든 요청에 사용자 정보가 포함되도록 개발자가 고생해야 한다
보안적인 문제도 생긴다.
대안2. 쿠키

쿠키에 저장되는 유저 정보 웹 브라우저는 쿠키라는 저장소가 존재한다. 이 저장소를 활용한다.
웹 브라우저는 쿠키라는 저장소가 존재한다. 이 저장소를 활용한다.

쿠키
- 사용처
- 사용자 로그인 세션 관리
- 광고 정보 트래킹
- 쿠키 정보는 항상 서버에 전송됨
- 네트워크 트래픽 추가 유발
- 최소한의 정보만 사용(세션 id, 인증 토큰)
- 서버에서 전송하지 않고, 웹 브라우저 내부에 데이터를 저장하려면 웹 스토리지 (localStorage, sessionStorage) 참고
* 주의 : 보안에 민감한 데이터는 저장하면 안됨! (주민번호, 신용카드 번호 등등)

쿠키의 생명 주기
- Set-Cookie: expires=Sat, 26-Dec-2020 04:39:21 GMT (만료일 되면 쿠키 삭제됨)
- Set-Cookie: max-age=3600 (3600초) - 0이나 음수를 지정하면 쿠키 삭제
- 세션 쿠키 : 만료 날짜를 생략하면 브라우저 종료까지만 유지
- 영속 쿠키 : 만료 날짜를 입력하면 해당 날짜까지 유지 ex) 로그인 후 브라우저를 닫으면 다시 로그인 시도해야 함.
쿠키 - 도메인 ex) domain=example.org
- 명시 : 명시한 문서 기준 도메인 + 서브 도메인 포함
- domain=example.org를 지정해서 쿠키 생성, example.org와 dev.example.org도 쿠키 접근 가능
- 생략 : 현재 문서 기준 도메인만 적용
- example.org 에서 쿠키를 생성하고 도메인 지정을 생략, example.org에서만 쿠키 접근, dev.example.org는 쿠키 접근 불가
쿠키 - 보안
- Secure
- 쿠키는 http, https를 구분하지 않고 전송
- Secure 적용하면 https인 경우에만 전송
- HttpOnly
- XSS 공격 방지
- 자바스크립트에서 접근 불가(document.cookie)
- HTTP 전송에만 사용
- SameSite
- XSRF 공격 방지
- 요청 도메인과 쿠키에 설정된 도메인이 같은 경우만 쿠키 전송
3. 캐시
캐시가 없을때

요청 결과로 1.1M 이미지를 받는다. 여기서 새로고침을 하거나 브라우저를 닫고 나중에 재요청을 한다면 똑같이 1.1M 이미지를 다시 받게 될 거다.

캐시가 없으면
데이터가 변경되지 않아도 계속 네트워크를 통해서 데이터를 다운 받는다. 인터넷 네트워크는 매우 느리고 비싸다
사용자는 브라우저 로딩 속도가 느린 걸 경험해야 한다.
여기서 캐시를 적용하면 다음과 같이 변한다.

1. 서버로 데이터를 받아온다.
2. 브라우저 캐시에 데이터가 저장된다.
3. 같은 요청을 보낼 때 캐시의 데이터를 불러온다.
캐시의 장점
캐시에 저장된 데이터는 네트워크를 사용 안 해도 된다. (비싼 네트워크 사용량이 감소)
사용자는 브라우저 로딩 속도가 빠른 걸 경험한다.
캐시 시간 초과 캐시 유효 시간이 초과하면, 서버를 통해 데이터를 다시 조회하고, 캐시를 갱신한다. (네트워크 다운로드가 발생한다)
4. 검증 헤더와 조건부 요청
캐시 시간 초과
캐시 유효 시간이 초과해서 서버에 다시 요청하면 다음 두 가지 상황이 나타난다.
1. 서버에서 기존 데이터를 변경함 (이미지 색깔만 바뀜)
2. 서버에서 기존 데이터를 변경하지 않음. (이전 이미지와 동일함)
캐시 만료 후에도 서버에서 데이터를 변경하지 않음
이럴 경우 저장된 캐시를 재사용할 수 있다. 단, 클라이언트의 데이터와 서버의 데이터가 같다는 사실을 확인할 방법이 필요

1. 응답에 Last-Modified를 추가하여 데이터 최종 정보를 보낸다.
2. 캐시 시간 초과 후에 요청하면 해당 캐시에 있는 데이터 최종 정보를 같이 서버에 보낸다.

3. 서버에서 데이터 최종 정보를 비교하여 변함이 없으면 메시지 바디없이 304 Not Modified + 헤더 메타 정보만 응답한다.
4. 클라이언트는 해당 캐시의 유효 시간만 갱신하여 재사용한다.
정리
결과적으로 네트워크 다운로드가 발생하지만, 용량이 적은 헤더 정보만 다운로드한다.
매우 실용적인 해결책이다. (많은 곳에서 사용한다)
'👩🏫 Study > 스프링부트 강의' 카테고리의 다른 글
| [4. 스프링 MVC 1편] 서블릿, JSP, MVC패턴 (0) | 2023.10.06 |
|---|---|
| [4. 스프링 MVC 1편] 웹 애플리케이션 이해 (0) | 2023.10.06 |
| [3. HTTP 웹 기본 지식] HTTP 기본과 메서드 (0) | 2023.10.06 |
| [3. HTTP 웹 기본 지식] 인터넷 네트워크 (0) | 2023.10.06 |
| [2. 스프링 핵심 원리] 컴포넌트 스캔 (0) | 2023.10.05 |